

How to scale blockchain data science for large datasets

Software Engineering, Blockchain, Basket, Science 🇮🇹🇬🇧🇫🇷 If I have seen further it is by standing on the shoulders of giants
Summary
In the last article I published, I discussed how to use Subsquid's SDK for data analysis, by saving processed data to local CSV files, instead of a database.
For this article, I want to talk about the natural follow-up in a "data analysis focussed" mini-series, which is writing data to Parquet files. The subject of this project is the Uniswap V3 smart contract, namely the data from its pools and positions held by investors.
The project discussed in this article is hosted on a GitHub repository:
Just be careful to select the parquet branch.
Note: the project was actually developed by one of Subsquid's core developers.
Introduction
CSV files are great for prototyping because they are easily inspectable by a human. They are super convenient, and, for smaller datasets, they are very portable. But this format has some drawbacks.
One of the most notorious ones is that in CSVs, the schema is not defined, and there are no data types included (only column names), but Subsquid’s library already manages this, by using strong typings offered by TypeScript.
Apart from this, CSV files start to become an issue for large datasets, because they tend to be a bit slow to import and parse and occupy significant space on disk.
When analyzing very large datasets, it's common to use distributed systems such as Hadoop, or Spark, and the workers in a cluster usually "divide and conquer" multiple files during the import process, but this cannot be done with CSV files.
This is where Parquet comes in handy:
Apache Parquet is an Open Source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk.
The Parquet format is designed to make data accessible in chunks, allowing efficient read/write operations without processing the entire file. Finally, Parquet files automatically include schema information and handle data encoding.
The choice of the project's subject fell on Uniswap, because the protocol generates a very large amount of information, and we have been using it for a while as a benchmark for our performance tests. Ultimately, this helps to better show how to leverage a more performance-oriented format.
Project setup
As with most squid ETLs, it all starts with creating a project from a template. If you haven’t already, you need to install Subsquid CLI, then, in a terminal, launch the command:
sqd init local-parquet-indexing -t evm
Here, local-parquet-indexing is the name we are going to give to our project, you can change it to anything you like. And -t evm specifies what template should be used and makes sure the setup will create a project from the EVM-indexing template.
Note: The template actually has more than what we need for this project. In the repository used for this article, I went on and removed unnecessary packages, so you can use this package.json.
The list of available commands has also been shortened, and
docker-compose.yml,schema.graphql, andsquid.yamlfiles have been removed because there's no need for them for this project.
Let's also install the dependencies, by launching this command:
npm i
Contracts' ABI
Because the project is not as trivial as indexing the transfers of a single token, some sections will be more complex and most of the code will be explained, rather than directly listed.
This paragraph about Abstract Binary Interface is no exception since this project indexes data from three contracts, one of which is a factory and uses a Multicall contract as well.
For this project, you will need:
The Uniswap V3 Factory smart contract address and ABI
The ABI of any of the Uniswap V3 Pool smart contracts deployed by the Factory
The Uniswap V3 Positions smart contract address, and ABI
The address of any deployed Maker DAO's Multicall smart contract. Luckily, Uniswap have their own
The ABI of an ERC-20 token (can be compiled from OpenZeppelin repository, or downloaded, for example from here, or from the repository of this article's project). Save it as
abi/ERC20.json.
Note: The project also uses
ERC20NameBytesandERC20SymbolBytesABIs, which OpenZeppelin defines inIERC20Metadata.solwhich is included inERC20.sol, so if you use this, you might have to change some imports inmappingsorutils.Note: for the pool ABI, you can inspect the internal transactions of one of the
Create Pooltransactions of the Factory, and look at the destination address, which will be the pool itself.
This means you'll need to generate TypeScript code for them, with multiple commands.
sqd typegen 0x1f98431c8ad98523631ae4a59f267346ea31f984#factory
sqd typegen 0xc36442b4a4522e871399cd717abdd847ab11fe88#NonfungiblePositionManager
sqd typegen 0x390a4d096ba2cc450e73b3113f562be949127ceb#pool
sqd typegen --multicall
sqd typegen <PATH_TO_ERC20_ABI>.json
This should have created a few files in the src/abi folder for you.
"Tables", "Database" and parquet files interface
The @subsquid/file-store library defines the Table and Database classes. The first one refers to the schema and types used for the different files, while the latter is the configuration of the interface with the processor that coordinates writing to these files.
These terms were chosen, because they maintain the same interfaces as classes used to write to actual databases, and the change is transparent for the indexer’s processor.
There are two main differences with the CSV article and the first one is that for this project, you'll need a library that was developed specifically for parquet files, so let's install it:
npm i @subsquid/file-store-parquet
The other one is that this project is more involved and is, in fact, using ten different tables instead of one.
It's advised to define these tables in a separate file, the original project has them under src/tables.ts. The syntax is pretty much the same as the CSV article, but the Table, Column, and Types classes are imported from the @subsquid/file-store-parquet library, rather than the CSV one. A special note to the newCompression class, which, as the name says, configures the parquet file's compression.
Here's an example:
import {Table, Column, Compression, Types} from '@subsquid/file-store-parquet'
export const Tokens = new Table(
'tokens.parquet',
{
blockNumber: Column(Types.Uint32()),
timestamp: Column(Types.Timestamp()),
contractAddress: Column(Types.String()),
symbol: Column(Types.String()),
name: Column(Types.String()),
totalSupply: Column(Types.Uint64()),
decimals: Column(Types.Uint16()),
},
{
compression: Compression.ZSTD,
}
)
The rest of the tables definitions can be found here.
Similarly, a src/db.ts file should be created to configure the Database class, which acts as the interface to the EvmBatchProcessor. By specifying the tables used, as well as the destination, and the size of the chunks in which the data is going to be split. Here are the contents of this file in full:
import assert from 'assert'
import {Database, LocalDest, Store} from '@subsquid/file-store'
import {
FactoryPairCreated,
PoolBurn,
PoolInitialize,
PoolMint,
PoolSwap,
PositionCollect,
PositionDecreaseLiquidity,
PositionIncreaseLiquidity,
PositionTransfer,
Tokens,
} from './tables'
import {PoolsRegistry} from './utils'
import {S3Dest} from '@subsquid/file-store-s3'
type Metadata = {
height: number
pools: string[]
}
export const db = new Database({
tables: {
Tokens,
FactoryPairCreated,
PoolInitialize,
PoolMint,
PoolBurn,
PoolSwap,
PositionCollect,
PositionDecreaseLiquidity,
PositionIncreaseLiquidity,
PositionTransfer,
},
dest: process.env.DEST === 'S3' ? new S3Dest('./uniswap', 'csv-store') : new LocalDest('./data'),
hooks: {
async onConnect(dest) {
if (await dest.exists('status.json')) {
let {height, pools}: Metadata = await dest.readFile('status.json').then(JSON.parse)
assert(Number.isSafeInteger(height))
let registry = PoolsRegistry.getRegistry()
for (let pool of pools) {
registry.add(pool)
}
return height
} else {
return -1
}
},
async onFlush(dest, range) {
let metadata: Metadata = {
height: range.to,
pools: PoolsRegistry.getRegistry().values(),
}
await dest.writeFile('status.json', JSON.stringify(metadata))
},
},
chunkSizeMb: 50,
})
export type Store_ = typeof db extends Database<infer R, any> ? Store<R> : never
Note: the
chunkSizeMbconfiguration defines the size (in MB) of a parquet file before it's saved on disk, and a new one is created.
Data indexing
The orchestration of the indexing logic is defined in the file named src/processor.ts:
import {EvmBatchProcessor} from '@subsquid/evm-processor'
import * as positionsAbi from './abi/NonfungiblePositionManager'
import * as factoryAbi from './abi/factory'
import * as poolAbi from './abi/pool'
import {db} from './db'
import {processFactory} from './mappings/factory'
import {processPools} from './mappings/pools'
import {FACTORY_ADDRESS, POSITIONS_ADDRESS} from './utils/constants'
import {processPositions} from './mappings/positions'
let processor = new EvmBatchProcessor()
.setBlockRange({from: 12369621})
.setDataSource({
archive: 'https://eth.archive.subsquid.io',
chain: process.env.ETH_CHAIN_NODE,
})
.addLog(FACTORY_ADDRESS, {
filter: [[factoryAbi.events.PoolCreated.topic]],
data: {
evmLog: {
topics: true,
data: true,
},
} as const,
})
.addLog([], {
filter: [
[
poolAbi.events.Burn.topic,
poolAbi.events.Mint.topic,
poolAbi.events.Initialize.topic,
poolAbi.events.Swap.topic,
],
],
data: {
evmLog: {
topics: true,
data: true,
},
} as const,
})
.addLog(POSITIONS_ADDRESS, {
filter: [
[
positionsAbi.events.IncreaseLiquidity.topic,
positionsAbi.events.DecreaseLiquidity.topic,
positionsAbi.events.Collect.topic,
positionsAbi.events.Transfer.topic,
],
],
data: {
evmLog: {
topics: true,
data: true,
},
} as const,
})
processor.run(db, async (ctx) => {
await processFactory(ctx)
await processPools(ctx)
await processPositions(ctx)
})
Here's a brief explanation of the code above:
The
EvmBatchProcessorclass is instantiated and parameters are set to connect to the Ethereum archive, as well as a blockchain node, requesting data after a certain block (make sure to add a node URL toETH_CHAIN_NODEvariable in the.envfile)It is also configured to request data for EVM logs generated by the Factory and Positions smart contracts, filtering for certain events (
PoolCreatedandIncreaseLiquidity,DecreaseLiquidity,Collect,Transfer, respectively)EVM logs data for any address, that complies with the topics of the Pool smart contract's events:
Burn,Mint,Initialize,Swapis also added to the configuration. This will guarantee that every time a new pool is created, the events it generates will be indexed.Finally, the processor is launched, and data is processed in batches, by functions defined in
src/mappings
For a brief explanation of whatprocessFactory, processPools, processPositions do, let's take the processPositions functions as an example:
it "unbundles" the batch of items received
for each item found it checks that it belongs to one of the pool addresses generated by the factory
verifies that it's an EVM log
compares the EVM log topic against the topics of the Events of position NFT contract registered in
processor.tsuses the corresponding Event TypeScript class to decode the EVM log
writes the decoded information to the corresponding table (parquet file)
To better understand how data is transformed, and how the other functions are defined as well, it's advised to browse the repository and inspect the code. Be sure to check the utils folder as well, as there are some auxiliary files and functions used in the mapping logic.
Start indexing
When the logic is fully implemented, to launch the project and start indexing, open a terminal and run these two commands:
sqd build
sqd process
The indexer should be able to catch up with the Ethereum blockchain, and reach the chain's head in less than an hour (took ~45 minutes while testing for this article). Bear in mind that this may vary a lot, depending on the Ethereum node used (Ankr public node in this case) and on your hardware.
The process will generate a series of sub-folders in the data folder, labelled after the block ranges where the data is coming from, and in each one of these folders there should be one *.parquet file for each of the tables we defined.
Data analysis
Since parquet files were essentially created to respond to the demands of data scientists, they are "native" to Pandas, and as such, they are imported as easily as CSVs (if not more).
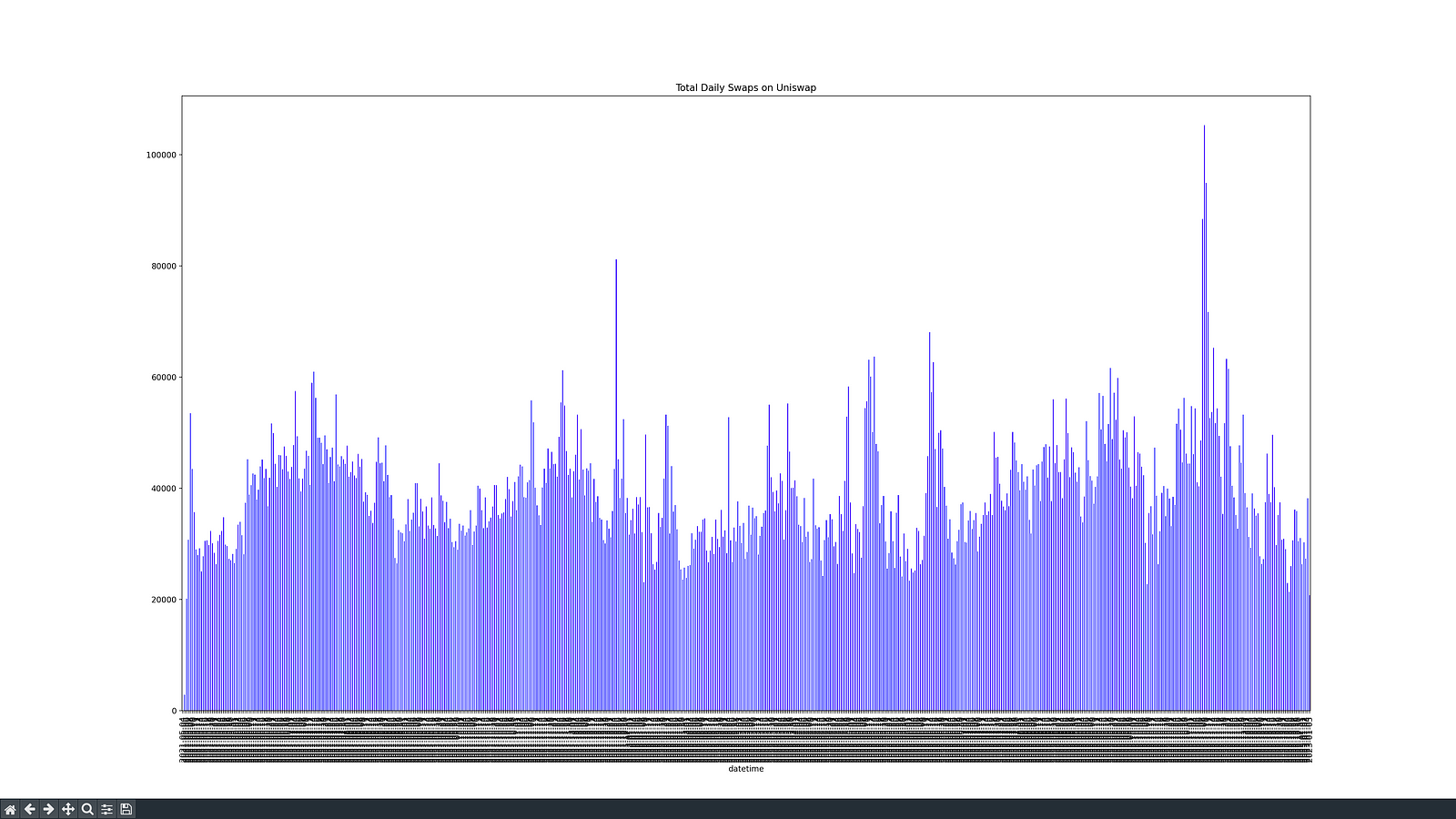
To provide a quick demonstration of how to handle the data generated by the indexer, here's a Python script that aggregates Swap events from all the parquet files in the data folder into a single DataFrame, converts the timestamp field to a DateTime type, groups by day, and counts the number of swaps that occurred each day, then plots a bar chart, like this one:
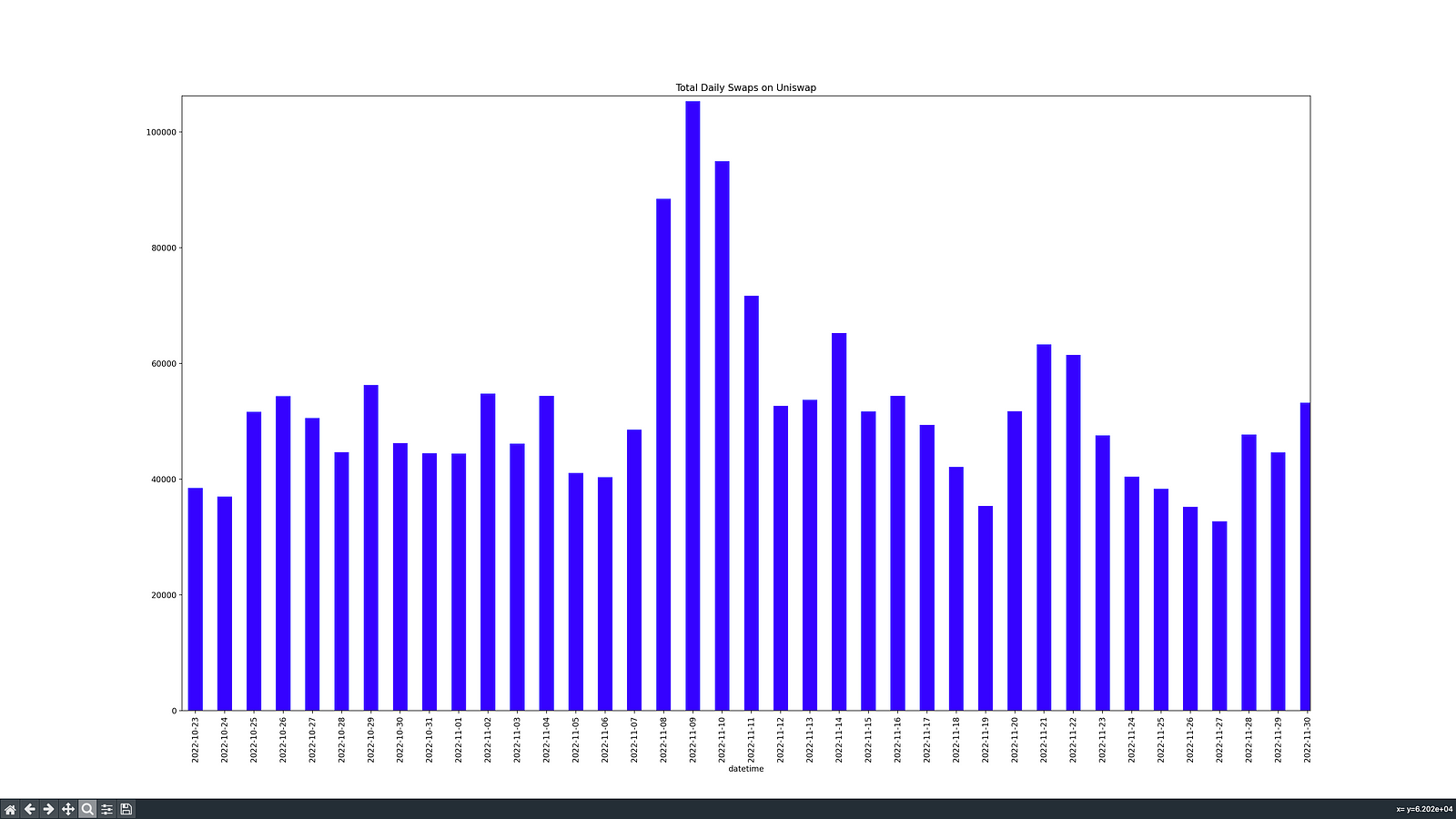
It's worth noting that the data traces back to May 2021, so the chart is quite squished, but it can be zoomed in using the toolbar at the bottom. Thanks to this, we can zoom in on the biggest spike in swaps, and find out that it occurred on November 9th, 2022, surrounded by two other days of very high numbers.
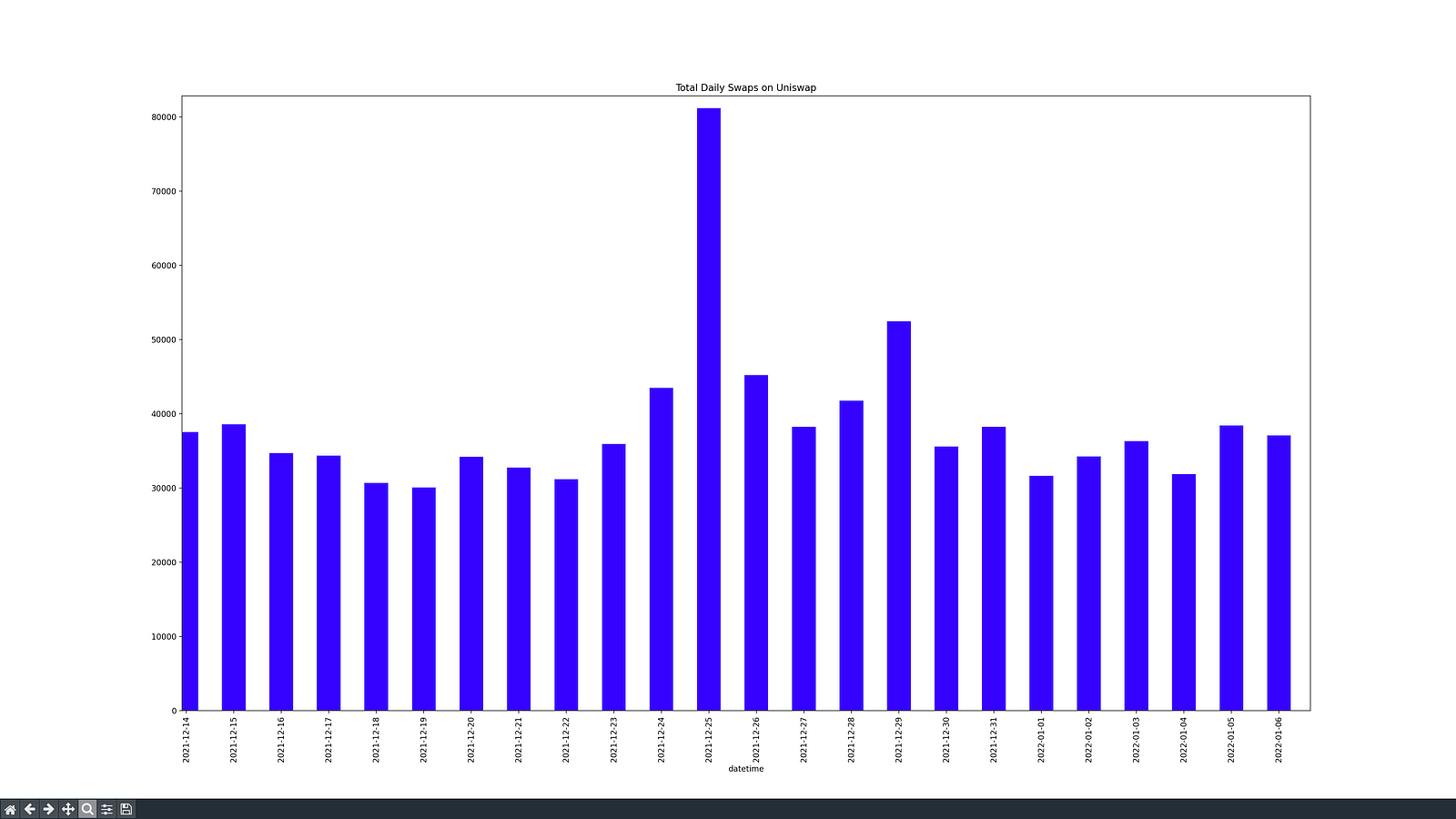
Funnily enough, the second highest peak, apart from the three days we just mentioned, occurred on Christmas day 2021:
Conclusions
For this article, the focus shifted from CSV to Parquet files. In contrast to CSV files, Parquet is a binary file format and can only be read with the proper tools. Python and Pandas are among these tools, and they are part of the average Data Analyst’s toolbox.
Each one of the two has its pros and cons, and they have different uses, so Subsquid wants to guarantee access to both, and let Data Analysts choose which format to use for their project.
To justify the use of Parquet, and test the performance, Uniswap V3 smart contracts were chosen as the subject of this project, indexing the data from its pools and positions held by investors.
To summarize: the project here described was able to index the entirety of Uniswap Pool events, across all the pools created by the Factory contract, as well as the Positions held by investors, in less than an hour (~45 minutes).
Note: Indexing time may vary, depending on the Ethereum node used (Ankr public node in this case) and on the hardware used.
Subsquids has been carefully listening to users’ requests for the past year, and the voices of blockchain data analysts have been heard. This is what motivated the development of libraries that allow saving to local files, and the research put into saving to file format specific to data-oriented disciplines.
This is why we want to continue collecting feedback on this new tool that Subsquid has made available for the developer community, so if you want to express an opinion, or have suggestions, feel free to reach out.
I want to see more projects like this one, follow me on social media, and most importantly, Subsquid.
Subsquid socials: Website | Twitter | Discord | LinkedIn | Telegram | GitHub | YouTube



